이중 y축 그래프, 값의 범위가 다른 두 그래프 함께 나타내기
정부에서 제공하는 코로나19 그래프를 보면,
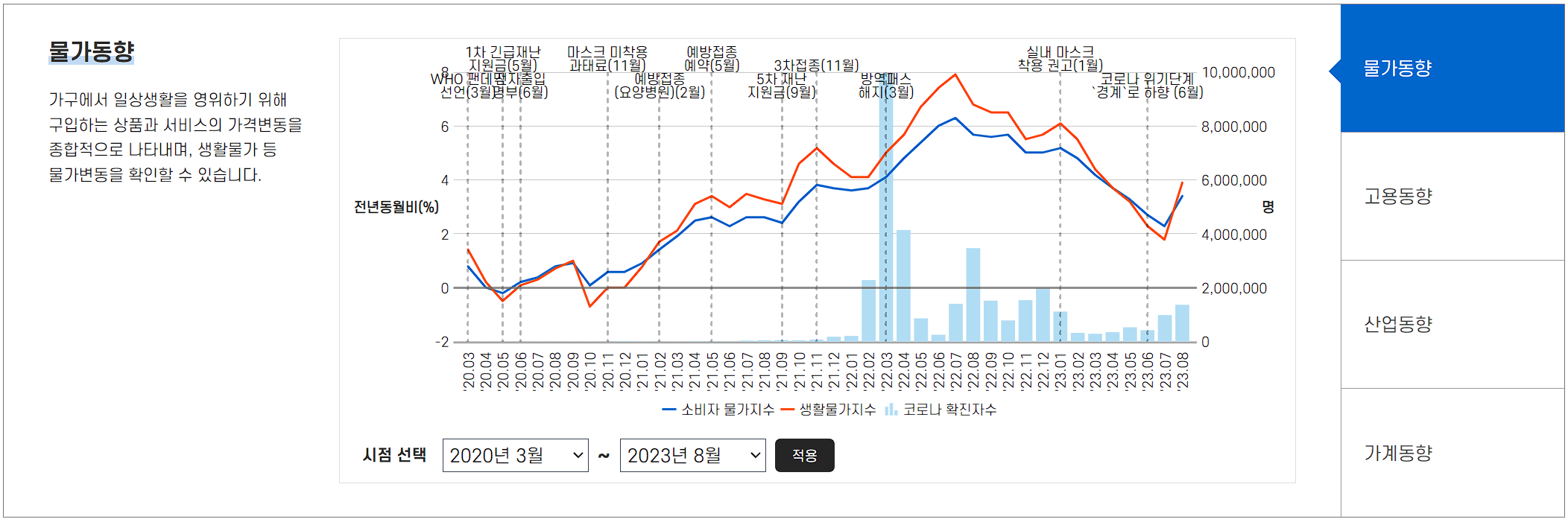
아래처럼, 코로나19와 연관있을 것으로 생각되고 코로나19 확진자 수와 함께 비교하고 싶은 다른 시계열 (물가동향) 자료를 함께 나타내는 경우가 많다.
당연히, R에서도 비슷하게 나타낼 수 있다!
이번 포스트에서 그려볼 그래프는 아래와 같다. (세로 선 + 텍스트 넣기는 다음 포스트에서 소개할 예정)

축이 두 개인 그래프 따라 그리기!
위의 통계청에서 제공하고 있는 그래프와 최대한 비슷하게 따라 그려볼 것이다.
[0] 준비
준비 1. 데이터 다운로드:
- 코로나19 확진자 수 (질병관리청) https://ncov.kdca.go.kr/bdBoardListR.do?brdId=1&brdGubun=11
- 소비자 물가 지수 (통계청) https://kosis.kr/statHtml/statHtml.do?orgId=101&tblId=DT_1J20002&conn_path=I2
- 생활 물가 지수 (통계청) https://kosis.kr/statHtml/statHtml.do?orgId=101&tblId=DT_1J20002&conn_path=I2
** 코로나바이러스감염증-19 페이지의 [발생동향] - [코로나19 양성자 감시 현황]의 맨 아래에 전수조사 다운 가능.
*** 통계청에서 데이터를 다운로드할 때 설정하면 좋은 옵션이 있다.
아래 사진에서 각 버튼을 클릭하면 아래 옵션이 설정 가능하다
(1) 시점: 2020.01 ~ 2023.08 (하나씩 누르지 말고, Shift를 통해 편하게 시점 선택 가능)
(2) 행렬 전환: 시점이 아래로 쌓이게 설정 (Drag & Drop 가능)
(3) 조회 설정: 필요한 값만 선택
(4) 증감률: "전년동월 대비 증감률" 선택
(5) 다운로드: 파일 형식은 csv의 ANSI, UTF-8는 한글이 깨짐..
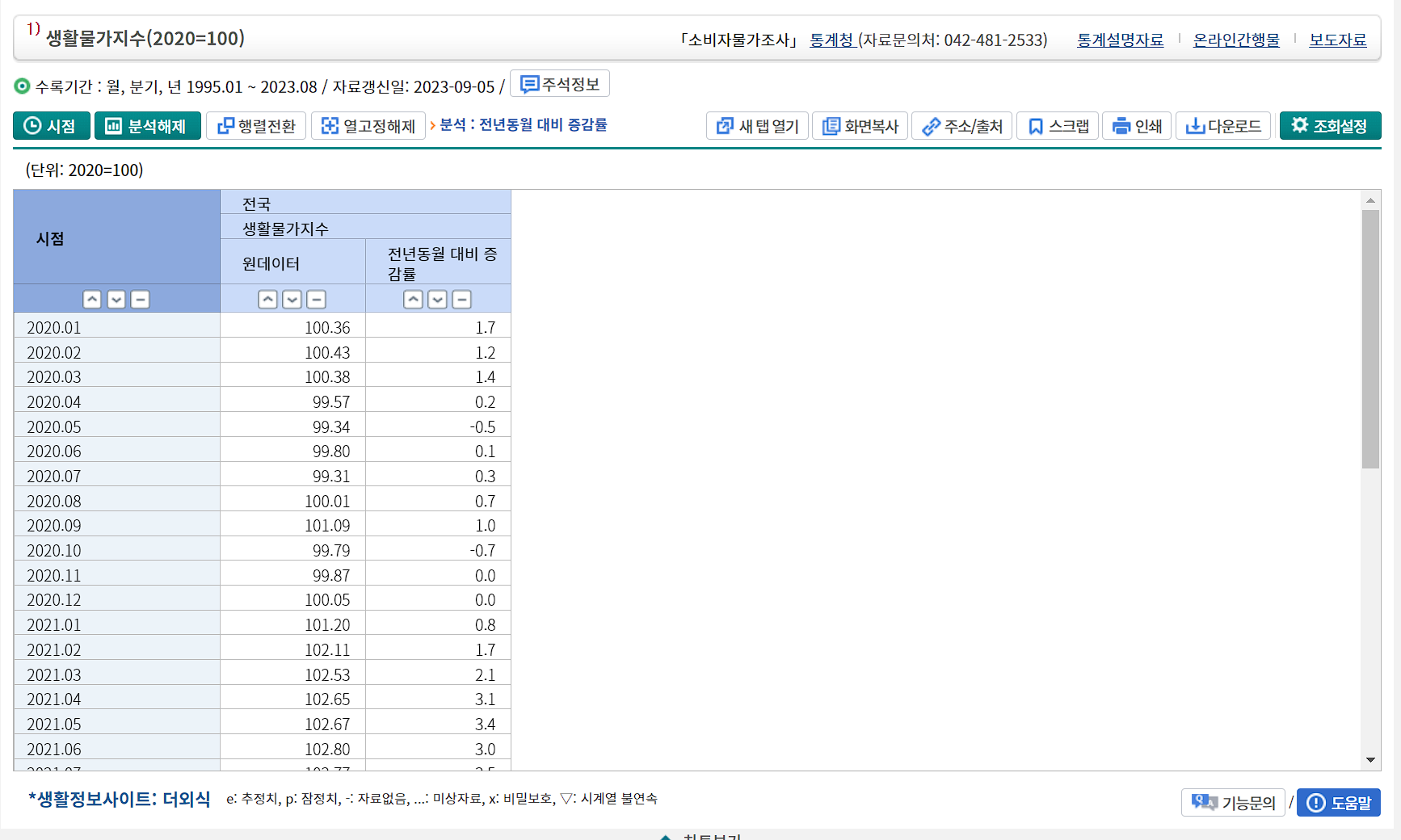
준비 2. 데이터 전처리
각각의 데이터는 1. covid_case, 2. sobija_moolga, 3. living_moolga 로 저장하였다. (직관적인게 최고!!)
주 내용이 아니기 때문에 전처리 과정 설명은 생략한다.
데이터 불러올 때, 원자료가 어떻게 생겼는지 확인하여 편한 방식으로 불러 왔으며,
head()와 str()을 통해 변수 타입 후 아래와 같이 전처리하였다.
library(readxl)
library(dplyr)
library(ggplot2)
covid_case <- read_excel("./covid_case.xlsx",
sheet=1, range="A7:C1326", col_names = c("일자", "계(명)", "국내발생(명)"))
living_moolga <- read.csv("./living_moolga.csv", fileEncoding="euc-kr")[c(-1,-2), ]
sobija_moolga <- read.csv("./sobija_moolga.csv", fileEncoding="euc-kr")[-1,]
# 코로나19 데이터는 일별이기에 월별 통합이 필요함.
covid_case <- covid_case[, c("일자", "국내발생(명)")]
colnames(covid_case) <- c("Date_ymd", "new_case")
# "-" 입력 0으로 수정
covid_case$new_case[covid_case$new_case == "-"] <- 0
covid_case$new_case <- as.numeric(covid_case$new_case)
covid_case$Date_ymd <- as.Date(as.character(covid_case$Date_ymd), "%Y-%m-%d")
# cut( , breaks=week)는 주별 통계 낼 때 쓰면 정말 편함.
covid_case$Date <- cut(covid_case$Date_ymd, breaks="month")
covid_case$Date <- as.Date(as.character(covid_case$Date), "%Y-%m-%d")
m_covid_case <- covid_case %>% group_by(Date) %>%
summarise(month_new_case = sum(new_case)) %>% data.frame()
# 날짜 형식: 내 데이터에 맞는 format 찾는 것 보다 흔하게 쓰이는 format에 내 데이터를 맞추는게 편함..
colnames(sobija_moolga) <- c("Date", "Index", "Increase_rate")
# 2020.01 (년도.월)로 표시되었기 때문에 일자 .01을 추가하여 format에 맞춤.
# 실제로 매월 1일의 데이터가 아니지만 편의상 사용
sobija_moolga$Date <- paste0(sobija_moolga$Date, ".01")
sobija_moolga$Date <- as.Date(sobija_moolga$Date, "%Y.%m.%d")
sobija_moolga$Increase_rate <- as.numeric(sobija_moolga$Increase_rate)
sobija_moolga$type <- "소비자 물가 지수"
colnames(living_moolga) <- c("Date", "Index", "Increase_rate")
living_moolga$Date <- paste0(living_moolga$Date, ".01")
living_moolga$Date <- as.Date(living_moolga$Date, "%Y.%m.%d")
living_moolga$Index <- as.numeric(living_moolga$Index)
living_moolga$Increase_rate <- as.numeric(living_moolga$Increase_rate)
living_moolga$type <- "생활 물가 지수"
# ggplot 그릴 때,
# 일별 & 소비자 물가 지수 & 생활 물가 지수 의 두 개의 Outcome이 있는 데이터로 만드는 것보다
# 일별 & Index & Type 으로 지정하는게 개인적으로 편함.
moolga <- rbind(sobija_moolga, living_moolga)월별 코로나19 확진자 수의 막대 그래프: geom_bar()
(1) geom_bar(stat="identity")
- 날짜 별 값이 주어졌을 때 사용.
- Default = "count" 로 주어진 항목에 대한 count plot을 그려주기 때문에, "Identity" 는 필수 설정해야 함.
(2) theme()
- lengend.position = "bottom": 범례는 항상 아래에 있는게 예쁜 것 같음.
- legend.title = element_blank(): 범례의 제목을 굳이 설명하지 않아도 될 때 사용.
- axis.text.x = element_text(angle=30, size=5): x축의 글자 형식 수정에 사용
# bar chart for covid new case
theme_set(theme_bw())
covid19_bar <- ggplot(m_covid_case, aes(x = Date, y = month_new_case)) +
geom_bar(stat = "identity")
# check
covid19_bar
# 상세 옵션 입력
covid19_bar <- covid19_bar +
scale_x_date(breaks=covid_case$Date, date_labels="%y/%m") +
theme(legend.position = "bottom",
legend.title = element_blank(),
axis.text.x = element_text(angle = 30, size=8)) +
ggtitle("Monthly COVID-19 Confirmed Cases") + xlab("Date")
# check
covid19_bar위의 코드를 작동시켰을 때 covid19_bar는 아래와 같이 그려진다.
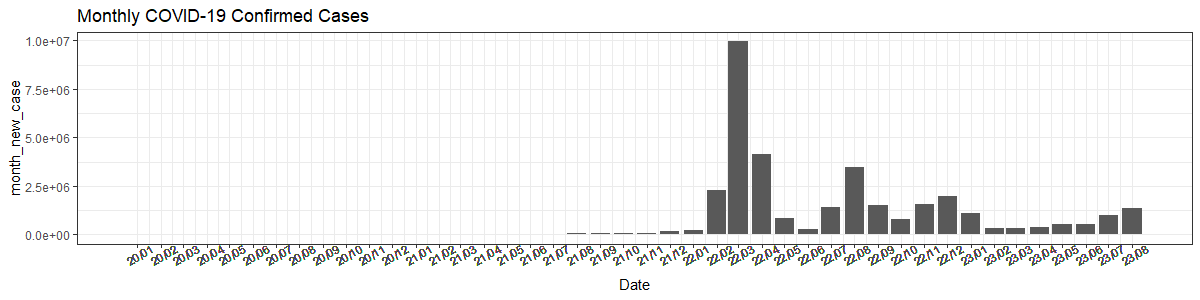
물가 동향의 선 그래프: geom_line()
(3) geom_line()
- color=type: 굳이 geom_line을 두 번 사용하지 않아도, 현재처럼 색깔을 알아서 구분해서 그려준다.
- moolga 로 데이터를 rbind() 한 이유
# line plot
index_line <- geom_line(data=moolga, aes(x = Date, y = Increase_rate, color=type) )
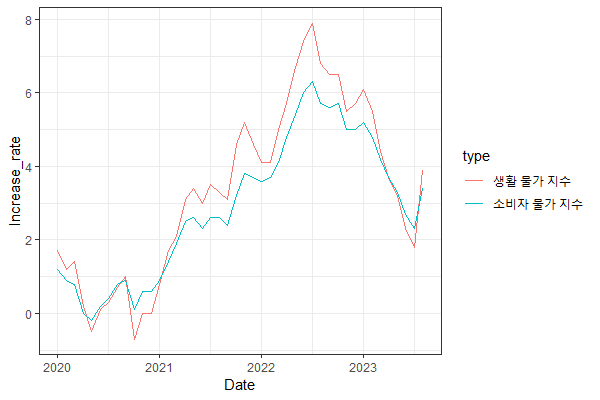
ggplot() + index_linetheme() 에서 소개했던 legend.position 과 legend.title 를 설정하지 않았을 때, 출력되는 결과는 아래와 같다.
확실히 Default 옵션이 별로인 것 같다. 대부분 legend.title은 굳이 출력하지 않아도 내용 전달에 아무 문제가 없다.
geom_bar() + geom_line()
위의 옵션을 사용하지 않고 그냥 합쳤을 때 결과는 아래와 같다.
실제로, 월별 코로나19 확진자 수는 78만~ 최대 100만의 범위 값을 갖는데, index 는 -1 ~ 8 사의 값을 가지기 때문에 하나의 축을 사용해서 그리면 index는 거의 0에 붙어있어야 하기 때문에 index 값의 변동성을 확인할 수 없다.
# 합쳐보기
covid19_bar + index_line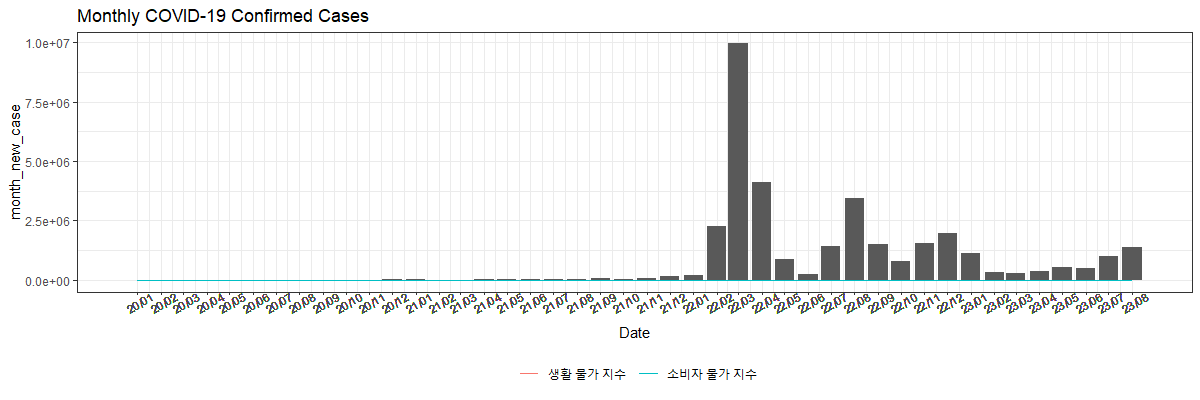
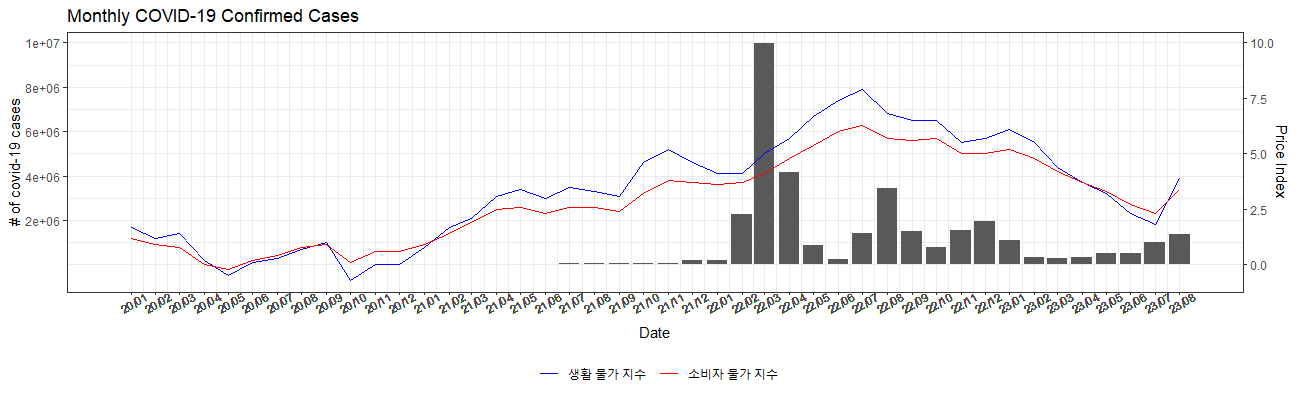
(4) scale_y_continuous() 와 sec.axis()
- y= Increase_rate * (1000000): 실제 값보다 뻥튀기하여 월별 코로나19 확진자 수의 같은 Range를 갖도록 한다.
- sec.axis = sec_axis(~.*(1/1000000), name = "Price Index" ): 뻥튀기를 위해 곱해진 값 만큼을 2차 축 설정할 때 나누어 주어, second axis 에서 나타내는 값이 실제 값과 같게 보이도록 설정해준다.
- (optional) "# of covid-19 cases": 첫 번 째 축 이름 설정함
- (optional) breaks= c(1:5 * 2000000): y축이 지저분하지 않게 20만 단위로 끊어서 나타냄.
- (optional) scale_color_manual(values = c('blue', 'red')): color = Type 으로 분리된 값의 색깔 지정 (개인적으로 ggplot2 기본 색상 질림)
covid19_bar + geom_line(data=moolga, aes(x = Date, y = Increase_rate * (1000000), color=type) ) +
scale_y_continuous("# of covid-19 cases", breaks= c(1:5 * 2000000),
sec.axis = sec_axis(~.*(1/1000000), name = "Price Index" ) ) +
scale_color_manual(values = c('blue', 'red'))
최종 결과는 다음과 같다.
'R Programming > Data Visualization' 카테고리의 다른 글
| [R] ggplot2 테마 적용으로 쉽게 그래프 꾸미기 (1) | 2023.11.02 |
|---|---|
| [R] ggplot 수직선, 수평선 그리기: vline, hline (0) | 2023.10.11 |
| [R] Useful Links for ggplot2 (0) | 2023.09.23 |
| [R] for 문으로 그래프 생성: ggplot2, for, assign, paste (0) | 2022.08.07 |
| [R] 여러 그래프 한 번에 나타내기 1: ggplot2, gridExtra (0) | 2022.07.24 |


