본 게시글은 R에서 실제 데이터를 사용하여 데이터에 결측치가 얼마나 있는지 확인한다.
결측 값이 구체적으로 어디에 있는지 확인하고, 이를 어떻게 처리할 수 있는지에 대해 다루겠다.
0. 데이터
분석에 사용하고자 하는 데이터는 ISLR 홈페이지의 resources에서 다운로드할 수 있다. (링크: https://www.statlearning.com/)
heart <- read.csv("./Heart.csv", row.names="X")
str(heart)1. 결측치 확인하기.
(1) summary() 함수
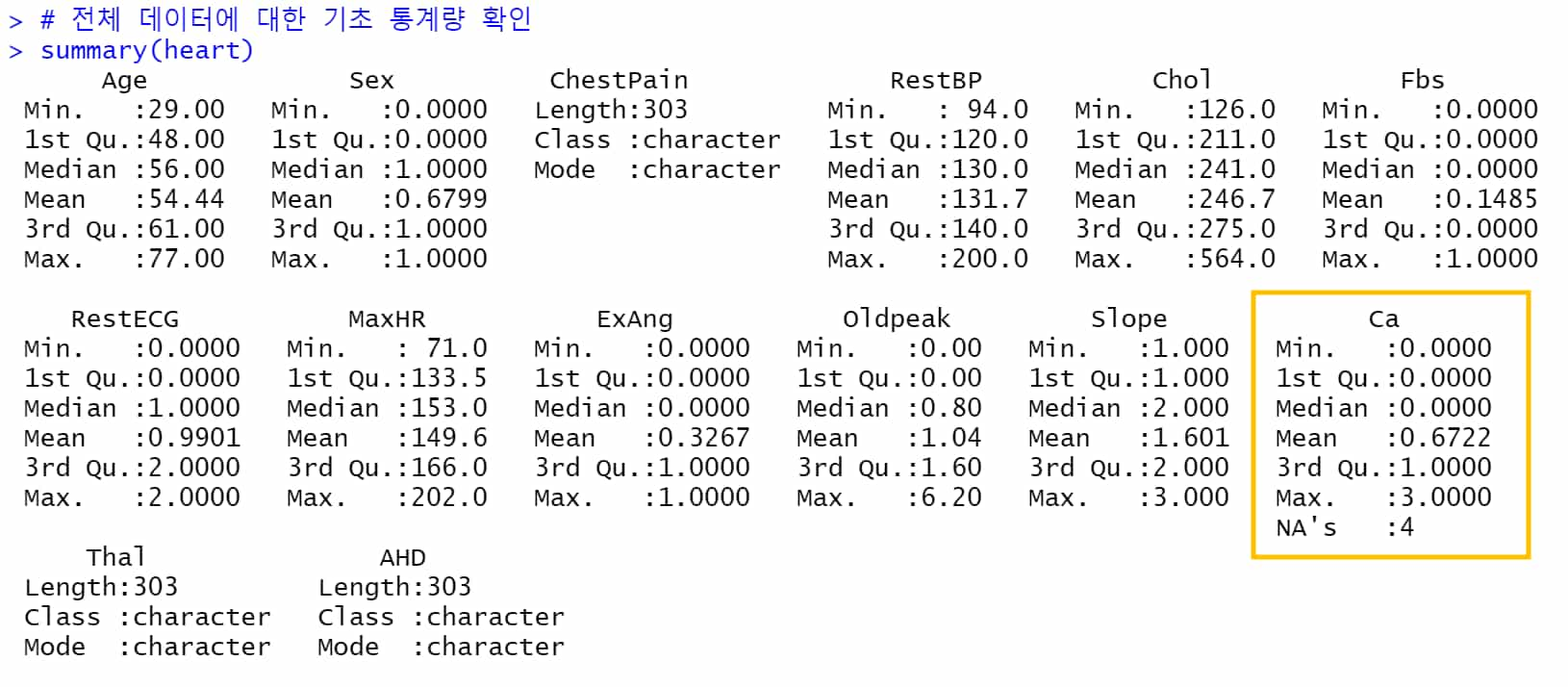
summary 함수는 입력된 데이터 프레임에 대한 기초 통계량을 출력하는 함수이다.
기본적으로 자료형 중 factor와 숫자 값에 결측이 있을 때, 결측 값의 수를 알려준다.
각 변수에 대한 최소값, Q1-Q3 등과 함께 결측이 존재할 때 NA's에서 결측의 수를 알려준다.
전반적으로 데이터를 확인하기에 좋은 함수이나, character형에 대해서 결측이 있어도 결측 정보를 제공하진 않는다.
# 전체 데이터에 대한 기초 통계량 확인
summary(heart)
(2) is.na()
is.na() 함수에 데이터를 input 값으로 넣으면 전체 원소에 대한 NA인지에 대한 여부를 TRUE/FALSE로 제공한다.
그렇기 때문에 데이터 프레임에서 직접 is.na를 사용하여 결측 값을 인덱싱할 수 있다.
is.na(heart)
heart[is.na(heart)]
(3) is.na() + sum(), colSums(), rowSums()
is.na가 각각의 원소를 TRUE/FALSE로 알려주고, R에선 TRUE 값을 1로, FALSE 값을 0으로 인식하기 때문에,
sum() 계열의 함수를 사용하여 보다 쉽게 결측치의 개수를 확인할 수 있다.
sum(is.na(heart))
colSums(is.na(heart))
rowSums(is.na(heart))
rowSums(is.na(heart))[rowSums(is.na(heart))>0]
2. 결측치 삭제
그렇다면 결측치를 어떻게 처리할 수 있을까?
(1) 분석에서 제외
기본적으로 R 내장함수는 Na를 처리할 수 있는 옵션을 제공한다. 보통은 na.rm 옵션이나 na.action 옵션을 사용한다.
na.rm 은 na를 제거할지 말지에 대해 물어보는 기능이다.
# 분석에서 제외
sum(heart$Ca, na.rm=TRUE)
mean(heart$Ca, na.rm=TRUE)
sd(heart$Ca, na.rm=TRUE)
원래 NA가 처리된 데이터의 모든 계산량은 NA로 출력되나, 이 기능을 쓰면 NA를 제외했을 때의 결과를 알려준다.

다음으로 na.action 에 대해 지정할 수도 있다.
보통 na.omit을 많이 사용하는데, na.omit은 na가 존재하는 사람(row)을 생략하고 분석해!라는 뜻이다.
glm(factor(AHD) ~ Ca, data=heart, na.action="na.omit", family="binomial")
분석에 사용한 AHD 와 Ca 변수에서 Na는 4개이다.
친절하게 아래에 결측으로 인하여 4개의 관측치가 삭제되었다.라는 메시지가 출력된다.

데이터 자체에서 Na를 영원히 삭제한 데이터를 얻을 수도 있다.
전체 데이터에서 사람(row)을 기준으로 na가 존재하는 6명의 사람을 제외한 데이터를 얻을 수 있다.
heart_del_na1 <- na.omit(heart);
dim(heart_del_na1) # n=297, p=14
3. 결측치 대체
일반적으로 "결측인 변수 ~ 다른 변수 (Outcome 제외한)"의 formula를 사용하여 결측인 변수를 예측하여 사용할 수도 있다.
아니면 한 사람이 반복 측정된 경우, 가장 최근의 값을 사용해도 된다.
또, 결측치에 전체 평균을 사용할 수도 있다. 어떠한 방법이든 measurement error가 생길 수 있다.
해당 데이터의 배경 지식을 고려하여, 어떻게 결측치를 대체할 수 있을지에 대해 충분한 고민이 필요하고,
데이터 샘플이 매우 매우 작아서 결측인 사람의 제외가 어렵거나, 각 변수별로 결측의 수가 매우 적은 경우엔 대체하는 것이 나을 수 있다.
마지막으로 R 결측치 대체에 가장 많이 사용하는 MICE (Multivariate Imputation by Chained Equations)에 대해 소개한다.
코드는 굉장히 간단하다. complete()을 통해, Na가 없는 데이터를 받을 수 있다.
이때 랜덤샘플링으로 총 5개(default)의 complete 데이터를 제공하는데, 3번째 데이터를 선택한 것이다.
library(mice)
m.heart <- mice(heart)
full.heart <- complete(m.heart, 3)
'R Programming > Basic' 카테고리의 다른 글
| Rdata 확장자 저장/불러오기 (0) | 2024.04.02 |
|---|---|
| [R] apply 함수 간단 예제 (apply, lapply, sapply) (2) | 2023.11.27 |
| R 사용자를 위한 Colab (0) | 2023.10.15 |
| R 데이터분석 문자열 전처리 paste, strsplit, str_detect (0) | 2023.10.01 |
| [R] 패키지 수동 설치 (0) | 2023.09.15 |

